Gemma-4 本地量化与部署全流程
Gemma-4 本地量化与部署全流程
本文记录了在 Windows 环境下,利用 N 卡 GPU 算力,通过 llama.cpp 从零开始下载、转换、量化并部署大型语言模型(以 gemma-4-26B-A4B-it 为例)的完整操作流程。
一、 环境准备与校验
在开始前,需确保系统的 CUDA 环境已正确配置。
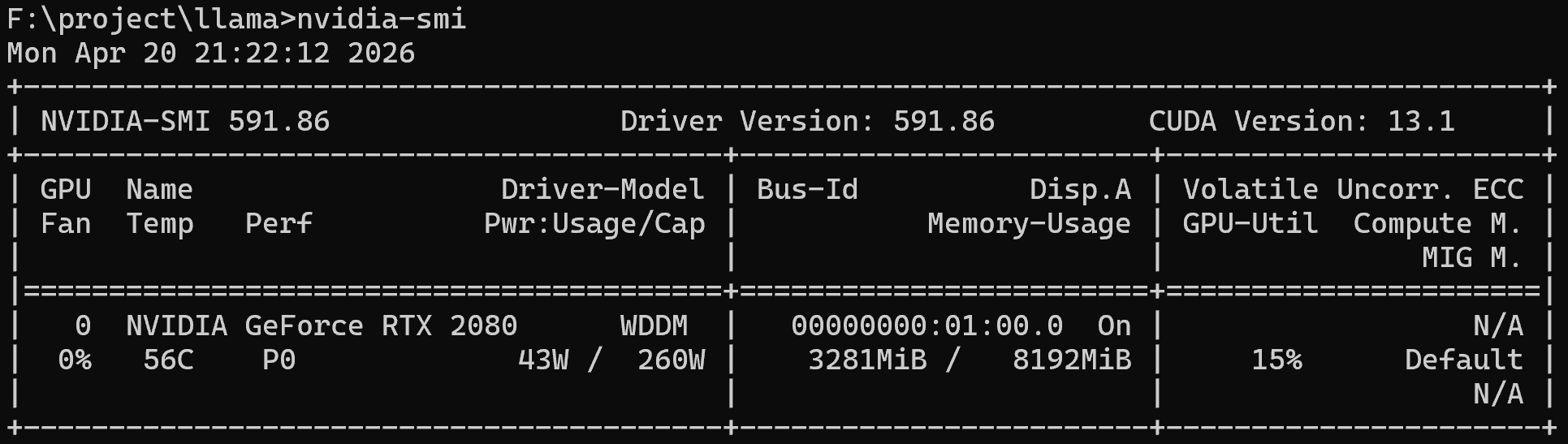
1. 检查显卡状态与驱动
nvidia-smi
2. 检查 CUDA 编译工具链 (nvcc)
nvcc --version

二、 工具与源码获取
我们需要同时下载 llama.cpp 的编译后版本(用于直接运行)和源码版本(用于执行 Python 转换脚本)。
- 开源地址: ggml-org/llama.cpp
- 工作区根目录:
F:\project\llama
1. 下载编译版 (Release)
下载对应 CUDA 版本的预编译包:Windows x64 (CUDA 13) 下载链接。
解压至工作区根目录:
F:\project\llama\
2. 下载源码版 (Source)
下载最新源码:Source Code (zip)。
解压至工作区下,重命名为 llama.cpp:
F:\project\llama\llama.cpp\
三、 模型下载 (ModelScope)
由于直接从 HuggingFace 下载可能存在网络不稳定的问题,这里采用阿里魔搭社区 (ModelScope) 结合 uv 环境进行高速下载。目标模型:google/gemma-4-26B-A4B-it。
1. 配置 Python 环境与依赖
# 使用 uv 极速添加依赖
uv add modelscope
2. 编写并运行下载脚本
创建一个 Python 脚本来拉取模型权重:
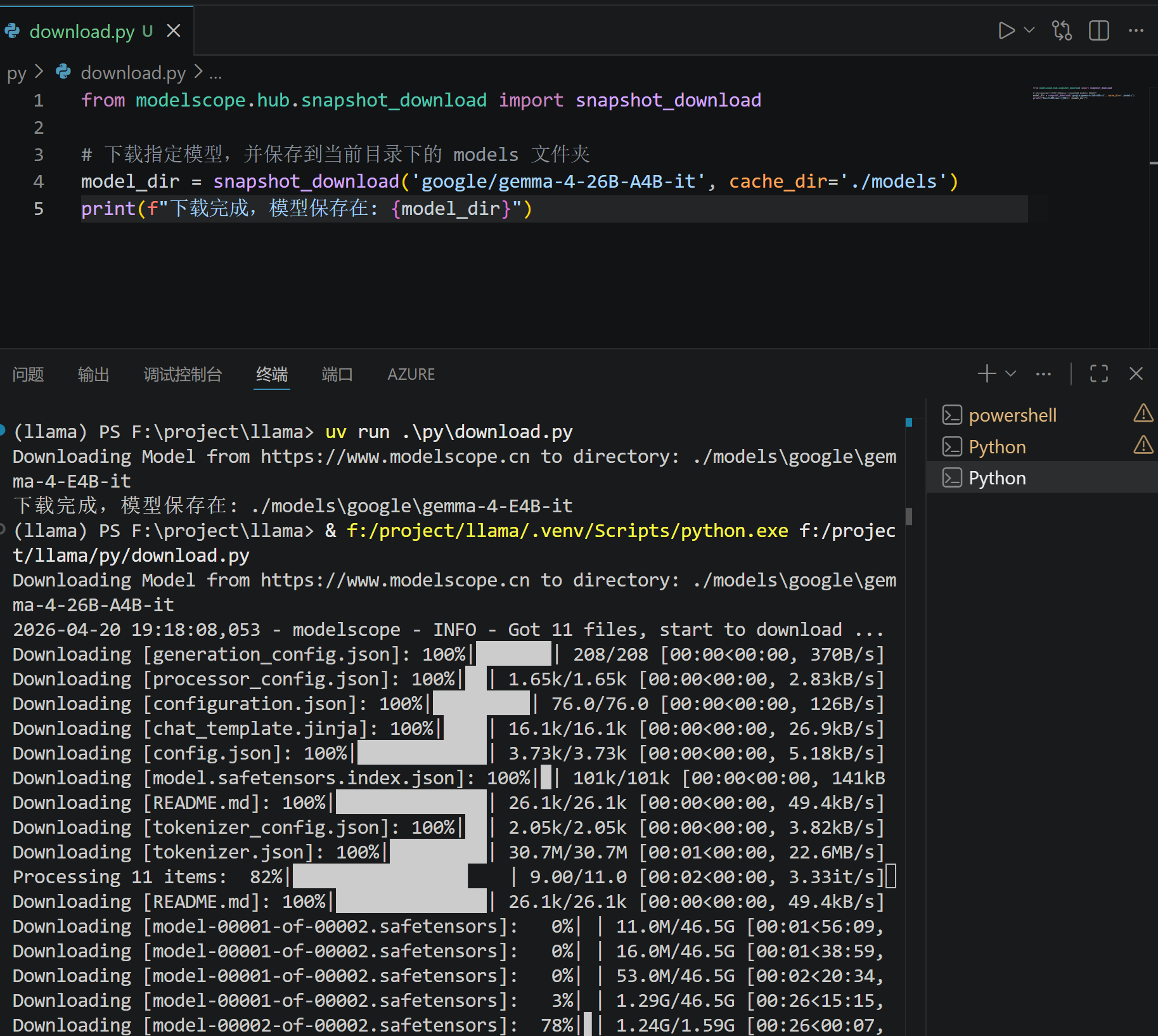
from modelscope.hub.snapshot_download import snapshot_download
# 下载指定模型,并保存到当前目录下的 models 文件夹
model_dir = snapshot_download('google/gemma-4-26B-A4B-it', cache_dir='./models')
print(f"下载完成,模型保存在: {model_dir}")
四、 权重转换与量化 (核心流程)
接下来将下载的原版权重转换为 llama.cpp 支持的 GGUF 格式,并进行量化压缩以适应本地显存。
1. 安装转换脚本依赖
进入源码目录,利用已有的 uv 虚拟环境安装依赖:

cd llama.cpp
# 极速解析并安装依赖
uv pip install -r requirements.txt --index-strategy unsafe-best-match
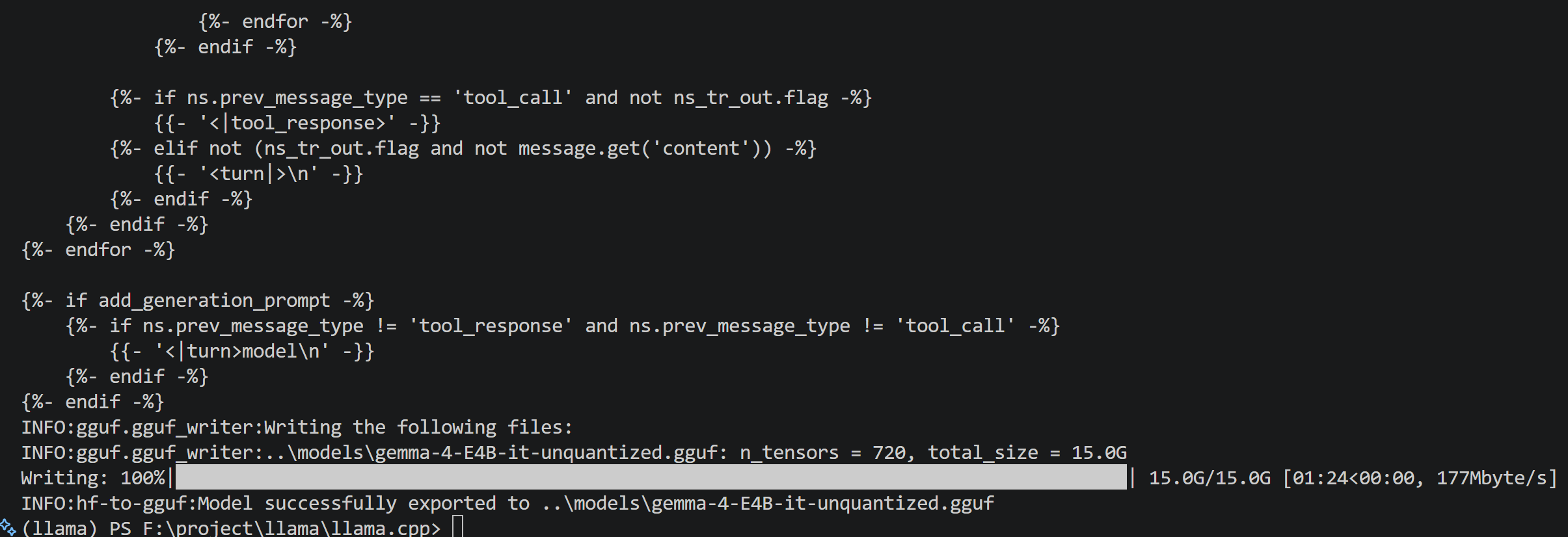
2. 转换为无损 GGUF 格式
运行转换脚本,将 HuggingFace 格式转为未量化的 GGUF。
(注:此过程极其消耗内存,需耐心等待)
python convert_hf_to_gguf.py ..\models\google\gemma-4-E4B-it --outfile ..\models\gemma-4-E4B-it-unquantized.gguf

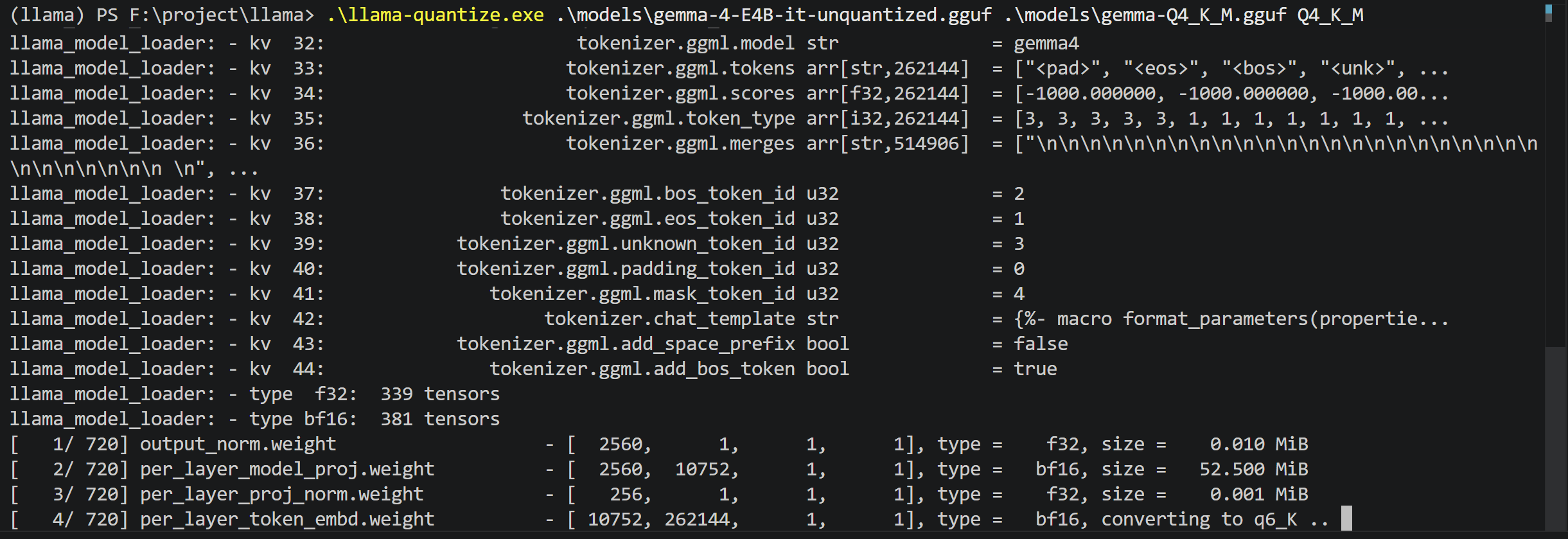
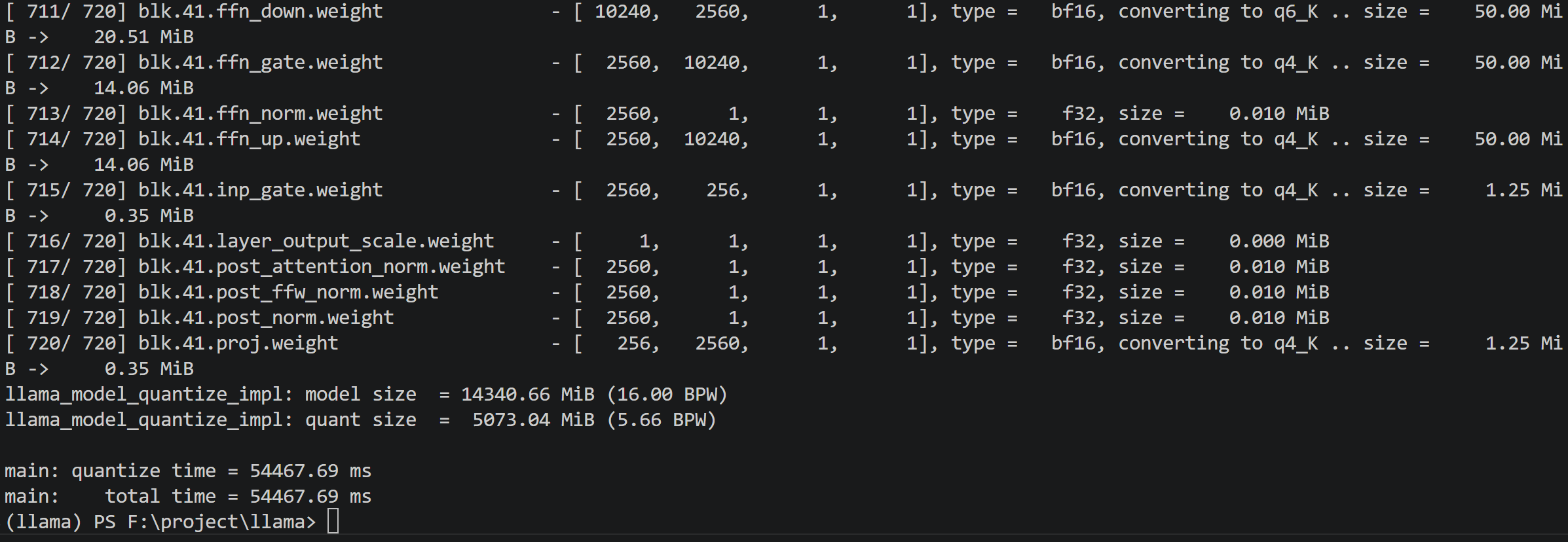
3. 模型量化 (Q4_K_M)
退回根目录,调用编译好的 llama-quantize.exe 将模型压缩为兼顾性能与显存的 Q4_K_M 格式。
cd ..
.\llama-quantize.exe .\models\gemma-4-E4B-it-unquantized.gguf .\models\gemma-Q4_K_M.gguf Q4_K_M
五、 本地部署与调用
模型准备完毕后,可以通过 Web 界面或命令行进行推理对话。
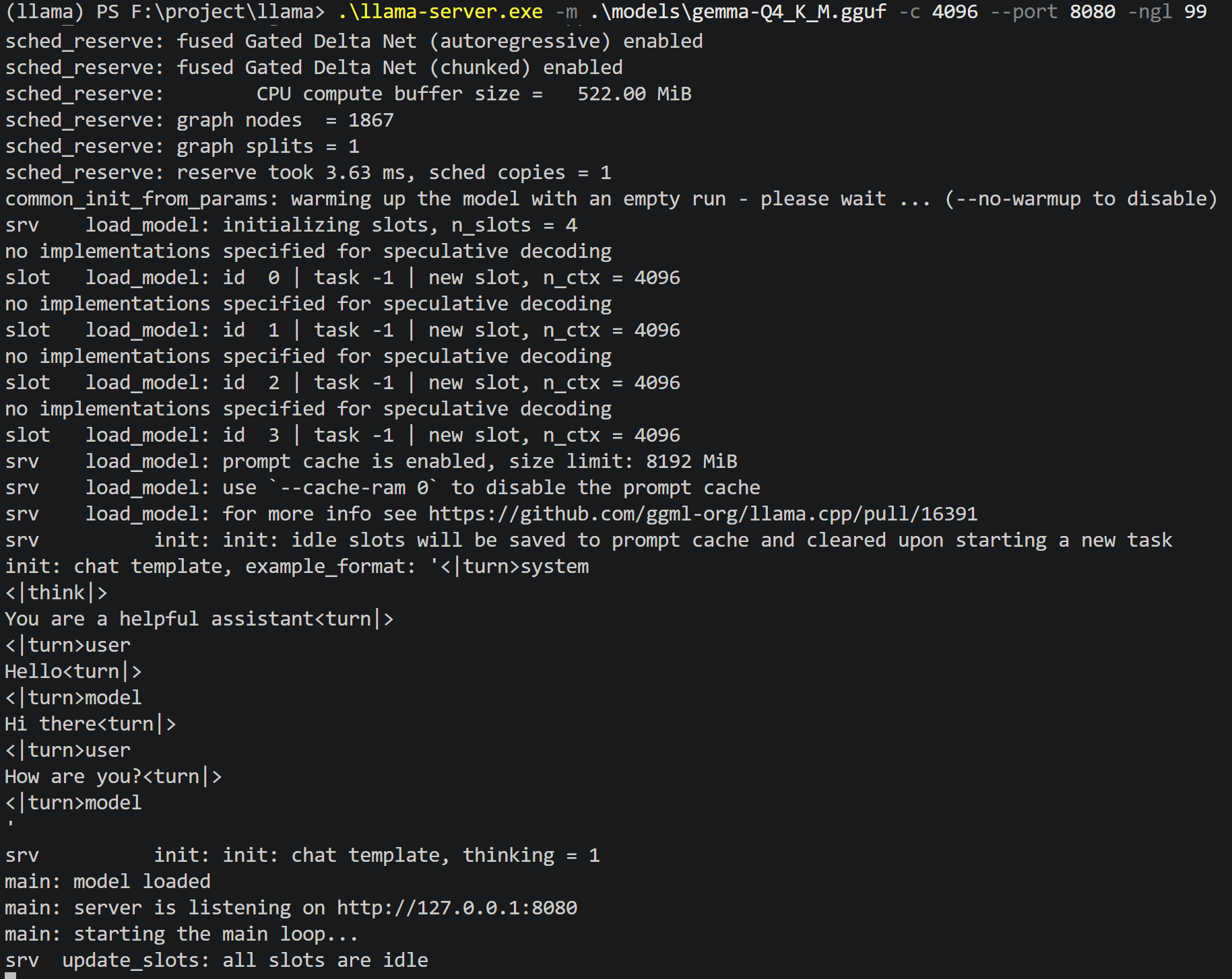
方案 A:启动 Web API 服务 (推荐)
启动一个兼容 OpenAI 格式的 API 接口,并附带图形化网页端。
.\llama-server.exe -m .\models\gemma-Q4_K_M.gguf -c 8192 --port 8080 -ngl 99 --host 0.0.0.0
参数详解:
-m:指定量化后的 GGUF 模型路径。-c 8192:设定 Context Window (上下文窗口) 为 8K。--port 8080:在本地 8080 端口提供服务。-ngl 99:核心参数 (Number of GPU Layers),将所有网络层卸载至 GPU 运行,获取极致速度。--host 0.0.0.0:解除本地环回限制,允许局域网内其他设备访问。
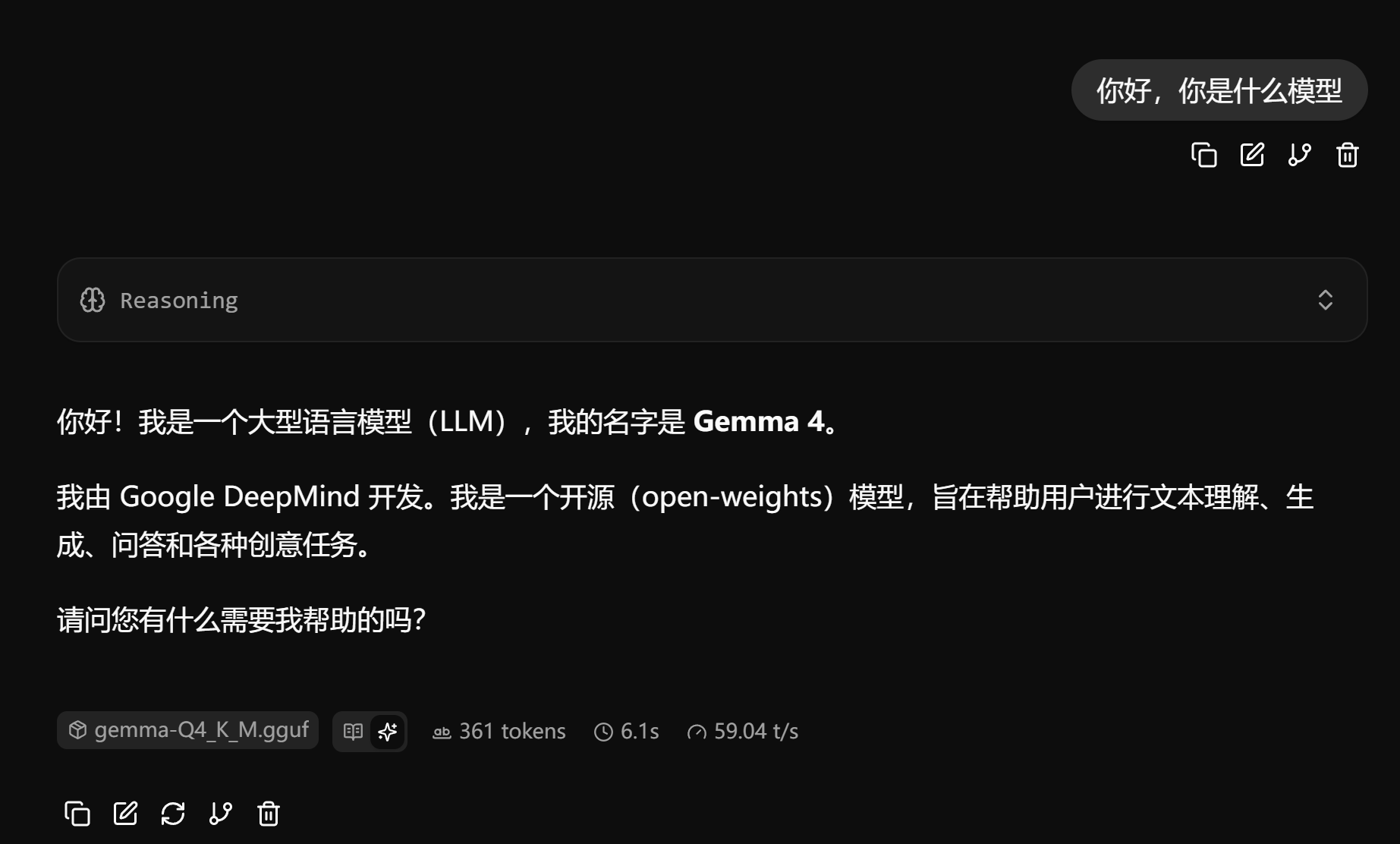
服务启动后,浏览器访问:http://127.0.0.1:8080 即可进入聊天界面。
方案 B:纯命令行极客模式
如果更偏好终端交互,可使用 llama-cli.exe 启动沉浸式对话。
.\llama-cli.exe -m .\models\gemma-Q4_K_M.gguf -c 4096 -ngl 99 -cnv
参数详解:
-cnv:开启持续对话模式 (Conversation)。使用Ctrl + C退出。